Article
MLOps for Robots: A Primer



August 26, 2022 ...

Machine learning operations (MLOps) is the discipline of delivering machine learning (ML) models through repeatable and efficient workflows. A relatively fresh concept compared with a decade ago, MLOps for robots—and MLOps generally—presents the potential to standardize workflows and make AI-based software development more efficient.
Here is why that matters:
As more ML algorithms move into production uses, a standardized workflow will help the success of development, deployment, operation, and CI/CD pipeline.
An MLOps culture will solidify engineering excellence and team mindsets for bettering ML model development and deployment, as DevOps does for software cycles.
The ultimate value is enabling business growth through better engineering processes and collaborative culture.
In this post, we will dive further into MLOps for robots use cases, look a bit more closely at MLOps for custom robot perception, and discuss the challenges of implementing such a workflow, as well as solutions for tailoring the approach based on an organization’s resources.

MLOps for Robots: Key Use Cases
Machine Learning algorithms have become an indispensable pillar for any robot to perform intelligent tasks. These algorithms are essential to support functions like perception, navigation (including operating things like a swerve drive), and robot control tasks, and as others discuss, the MLOps for robots methodology is universally valuable for anything related to ML applications.
A Perception Use Case: Object Detection and Multi-Modal Sensor Fusion
To create a perceptive robot via machine vision technology, a confluence of sensors such as camera and ultrasound are required, including LiDAR and RADAR for three-dimensional perception. ML models give robots the intelligence they need to connect the dots and perceive their surroundings through computer vision, object detection, tracking, semantic segmentation, and learning-based sensor fusion.
As the perception complexity increases, MLOps helps cater ML models for various applications.
A Robot Navigation and Control Use Case: Reinforcement Learning (RL) for Stationary and Mobile Robots
Controls leverage sensor data to actuate a system or a machine’s equipment to behave as desired, which is the case for both stationary and mobile robots. A legged robot can be trained to walk in a similar way to animals and humans through probabilistic trial, error, and ‘rewards’ methodology termed as reinforcement learning (RL).
The development of RL is much more efficient with a mature MLOps process in place because the iterative training nature of developing RL algorithms goes hand in hand with standard MLOps for robots practices like version control of the developed models and automated deployment and production.

ML Ops for Robots Case Study: A Deep Dive into Fresh’s Perception Use Case
To better understand setting up an MLOps for robots process, as well as planning for iterations, let’s dive deeper into a perception use case for the robot we are in the process of building in an internal research & development project.
We are currently working on a robot prototype that, in its first iteration, can navigate autonomously on one floor of an office building. Offices are full of activity, with people moving between meetings, spaces that shift and evolve with reorganization, and things like glass doors that make it difficult for autonomous robots to navigate predictably and safely. As one would expect, object detection is essential in this case. Machine learning models (specifically deep learning, a type of AI learning model) help the robot accomplish complex perception challenges like recognizing a glass door in a visually convoluted environment.
To train such a model that is both reliable and scalable, a repeatable and reliable workflow is required. MLOps serves this exact purpose.
Workflow Management
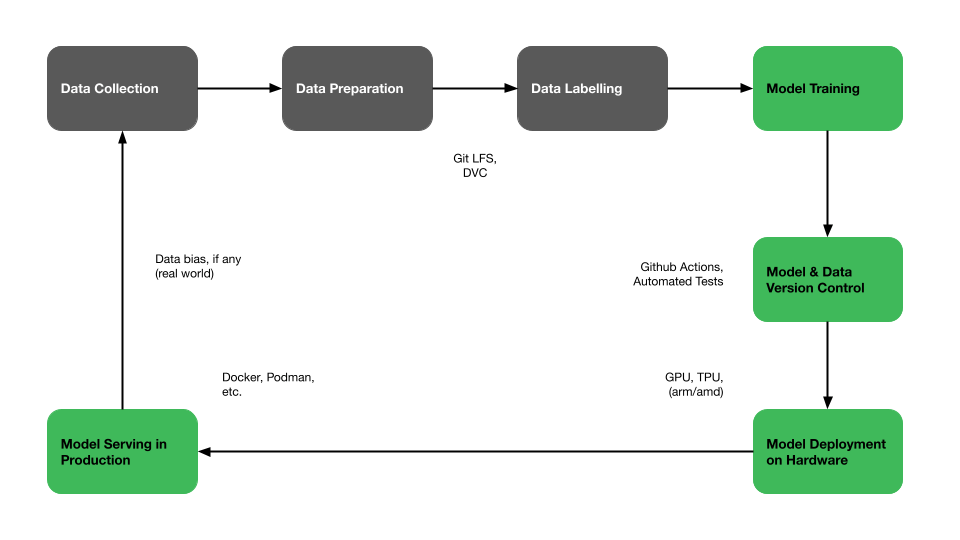
Training a robot to perceive and respond requires data collection, data labeling, model training, data and model iteration, integration, and deployment. MLOps for robots governs the approach, as illustrated in the graphic below:
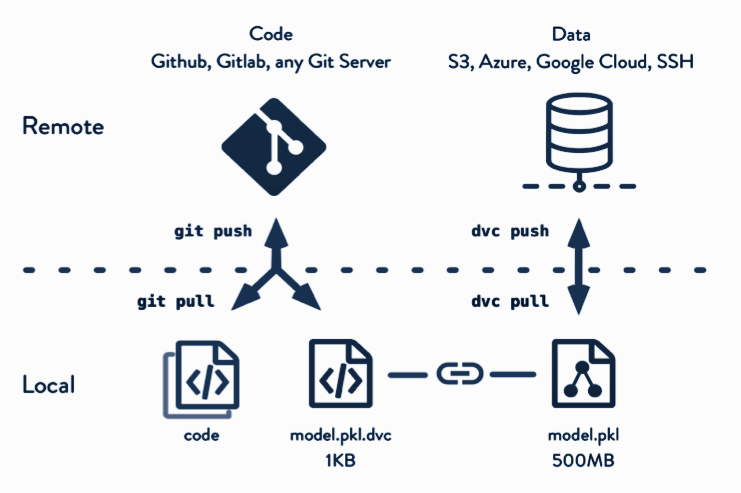
Code & Data Versioning
For scalability and reproducibility of the end deployment, one needs to take care of the data and also the model(s). Keeping track of the data and model(s) for every iteration of training and validation is essential.
A code and data versioning workflow helps us in the following ways:
- Tracks every process involved, from data collection to end deployment (similar to version control of code for general software development)
- Ensures that data preparation, data labeling, and feature engineering are executed through a controlled peer-review process.
- Lays a platform for team collaboration for the model creation and training
- Enables parallel experimentation with the ML/DL models
- Helps in automating the production deployment pipelines and maintains a healthy log of predictions from the model deployments
Data Preparation
MLOps, with the perception use case and others, allows you to get to uncertainties about data and model development sooner. In the ML world, the model is only as good as your data, which should be carefully curated:
- Data should be cleaned for any missing labels and other defects.
- Data should be comprehensive, covering some edge cases to help in the ML/DL model generalization.
- Data should be filtered and augmented with some level of pre-processing.
In the perception use case, the types of the data we work with are:
- RGB (red-green-blue) images
- RGB-D (red-green-blue-depth) frames from the cameras, and
- PCD (point cloud data, or the ability for the robot to visualize three-dimensional objects in space) from the LiDAR.
The RGB images are pre-processed by performing lateral flips, pixel normalization, etcetera, and the point cloud data is filtered or scaled down before feeding it to an ML model.
Model Training & Validation
ML algorithms analyze training data and learn to predict accurately using the error metric between the predictions and true target; for example, the prediction of glass door with the actual glass door label and a prediction of wooden door with the respective label. Amazon’s documentation on Machine Learning provides a more in-depth discussion.
In our perception use case, we train a deep learning model to identify and differentiate between a glass door and a wooden door. Feeding the model with training data (pictures) containing the target attributes (glass and wooden doors), the model will learn and eventually help the robot to differentiate and recognize the doors during its missions. To make the model generalizable for different office spaces, several iterations of data collection, data augmentation, and the model training are completed. During this iterative process, hyperparameters dictate the ML model performance as much as the data itself, so MLOps for robots also helps to keep track of the models for their parameter tuning.
Model Deployment CI/CD (Continuous Integration/Continuous Deployment)
CI/CD is a common process for DevOps teams that amounts to a method of committing small code changes more frequently in order to maintain a robust, thoroughly tested, peer-reviewed code base.
Identifying smaller errors or quality issues such as data bias for a given ML/DL model is much easier with thorough logging and versioning, hence the importance of CI/CD.
Engineering Refinement
This is connected to CI/CD. After advances are made, code can be pulled for alternative builds, configured for different reasons, or tested against other environments.
At Fresh, we encounter this for the model deployment on different hardware architectures (AMD/ARM).
Data Model Development Iterations
The CI/CD process can eventually be automated; running dozens of development iterations unveils new patterns in the data and new possibilities for the robot to improve its perception abilities.

Recommended Tools, Conventions, and Platforms
MLOps for robots—and MLOps in general—is a growing field, and there are numerous tools, conventions, and platforms to consider. Here are some of the tools to start with:
Here is an example of the tools (and integrations) one could use to easily start with in adopting the MLOps for robots practice:
- Setting up Github actions for automated model testing and model versioning
- Using Git LFS for storing the models and associating them with the correct data using DVC
- Delivering the ML models and the integrated software using Docker.
Two Common MLOps for Robots Challenges to Anticipate
Implementing a reliable MLOps workflow takes time and care, but ultimately, the result of creating reliable ML models speaks for itself. Here are several challenges we see, with advice on how to proceed.
“Our organization is too small to implement such a process.”
Another important consideration when it comes to MLOps is the different roles in the chain. Those involved should be a technical PO, data engineer, data scientist, ML Engineer, software engineer, and an MLOps Specialist. The last is a cross-domain role with a background in software DevOps with a Machine Learning specialization.
Large organizations with processes in place have a matrixed team of specialists (as mentioned) above to handle different aspects of the process. Smaller teams might not have the same resources but have the advantage of being more nimble and agile.
The goal of MLOps is reliable models and ultimately client satisfaction (whoever the client or stakeholder is). There are different ways to get to that goal, and smaller teams will need to be realistic in analyzing what elements of the MLOps process they should prioritize, what they can reasonably sustain, and how detailed to get.
“Our timeline won’t allow for MLOps.”
An academic AI research team’s goal is to research and develop novel ML/DL models and not necessarily worry about the deployment and production maintenance of the models. So the MLOps practice for academic research teams can be applied to versioning, which can aid in developing the best versions of their newly created ML/DL models.
On the other hand, a massive tech organization seeking to go to market faster than the competition can implement a robust MLOps platform to expedite model development and automation of the model serving. They can spend more money, hire more specialized engineers, and solve the challenge.
Fresh fits into a third category: a mid-sized engineering company that understands how to balance rigor and practicality. We have the unique ability to meet clients and partners wherever they are in the process, and provide the consultative expertise to implement MLOps even if the program is not as sophisticated as a tech giant.
In any case, implementing an MLOps for robots program takes time and resources. But the ROI is time and resources saved in the long run, as well as proven ML models.

MLOps for robots proves your hardware faster, with more reliability and accuracy
One of the major factors driving the MLOps initiative at Fresh is ensuring our robots’ perception is reliable and accurate. Used in this way, MLOps:
- Allows all engineers to be on the same page, with agreed-upon references and model metrics
- Accumulates knowledge, reusable datasets, and repurposable ML models and code base
- Automated deployment and model serving for production on different hardware platforms.
These outputs are relevant and valuable for any organization seeking to create reliable ML models.
If you are interested in learning more about how to stand up an MLOps for robots program, are interested in discussing more, or want to learn more about the innovative things we are doing at Fresh, we would love to connect.