Article
Building a Robust Perception Library for Robots



August 30, 2022 ...

Due to many implementation nuances, intelligent and performant robotic perception is hard to get right. That’s why creating a perception library for robots is essential.
A portfolio of datasets, tools, inferencing methods, deployment tactics, and practice guidelines provides the building blocks for establishing perception workflows with better assurance and efficiency than a case-by-case approach. Such a portfolio reflects a systematic, holistic, and strategic philosophy for building a robust perception library for custom robots, which is central to the extensibility that we’re after in creating The Harmony Program.
This post will explore:
- The various challenges around perception for robots
- Our systematic approach to overcoming those challenges at Fresh
- The building blocks our work is producing for creating scalable autonomous solutions
The challenge of perception for robots
For humans, perception refers to the ability to see, hear, touch, smell, taste or become aware of something through the senses, which involves recognizing environmental stimuli and actions in response to these stimuli.
In robotics, using a primitive analogy with humans, perception performs physical scene understanding (perceive, comprehend, and reason) to provide information to robots, aiming to support robot navigation in the scene and interactions with the scene.
There have been dumb or smart robot debates from different perspectives. The ‘smartness’ of perception is one key intelligence level gauge for a robot. Artificial intelligence (AI) technologies have shown promising potential in assisting robot vision, haptics, and voice perceptions for mapping, localization, navigation, object detection and tracking, walking, pick-n-place, and human-to-robot interaction tasks, respectively. The engineering community has been relentlessly working toward enhancing robotic intelligence to close the perception-action loop for robots. With the Harmony Program, the Fresh robotics team joins forces with the community to advance robotics through continuous learning, exercising, and optimization.
Our effort leverages the latest and appropriate technologies to build intelligent, scalable, and human-collaborative robotic and autonomous solutions for clients and provide cornerstones for commercializing new products in the robotics engineering field through techniques like:
- Simulation for software-hardware project development
- MLOps and other development processes
- Improving AI for robotics
- Harnessing new technology platforms to expedite development

Perception is nuanced
The ability to perceive and interact with surrounding objects and the environment via machine vision is critical to robots’ functionality. Given the variety of use cases, environmental characteristics, robot form factors and operating systems, computing power limits, sensor specs, and data types, as well as human factors, there are often quite a lot of constraints in implementing perception functions for robots.
The nuances associated with these constraints, small or big, would have different impacts on the system architecture, components downselection, software implementation, and perception algorithm performance. This places a challenge on the engineering tradeoffs and cost-effectiveness for realizing robot perception functionality.
The Harmony perception workflow
It makes better sense to cope with this engineering challenge using a systematic and holistic scheme instead of a case-by-case approach. We’ve started building the Harmony Perception Library, which contains multiple use cases and a four-stage perception workflow to fulfill this scheme.
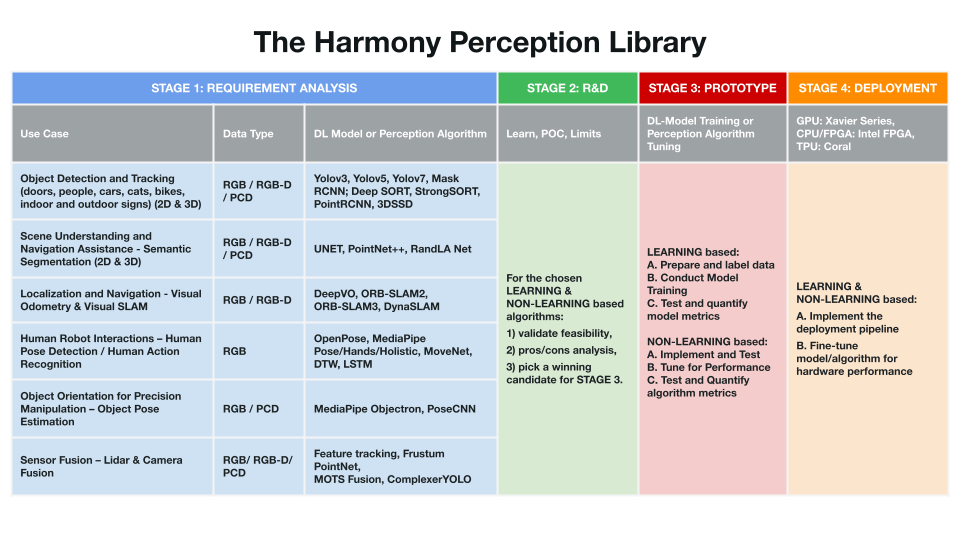
We intend to use the four stages (as shown in the horizontal aspect of the Library) as an end-to-end guide rail for our perception workflow. Let’s elaborate on our thought process in establishing this guide-rail.

Stage 1: Requirement Analysis
At an abstract level, a robotic perception system consists of three critical components: data and data type from sensors, data representation, and the conventional or learning-based perception algorithm to process the data for reasoning purposes.
For conventional perception algorithms, fine-tuning certain parameters would produce performant perception solutions. For learning-based algorithms, the training data and the learning model are both valuable components. We’ll focus more on the learning-based algorithms here.
Following the data and the learning-based algorithms connecting with the use case requirements, certain appropriate candidates can be selected for further screening in Stage 2. For example, if a use case is to detect objects such as cars and people we could either use RGB, RGB-D or PCD (point cloud data) data types depending on the sensor such as RGB/RGB-D from cameras or PCD from a Lidar. After this, the appropriate DL models could be chosen from a pool of candidates for object detection.
Stage 2: R&D
In this stage, a proof-of-concept (POC) study is conducted to validate the feasibility and identify the engineering limitations of the chosen candidate models. The POC study usually runs the DL-model inferences on the given sample data from the use case using pre-trained parameters for these models. We can then analyze the models for various tradeoffs between the required evaluation metrics for selection. There would typically be a winning candidate at the end of this stage.
Stage 3: Prototype
In the Prototype stage, we prepare and label the training/testing data and conduct model training for the winning candidate from Stage 2. At this stage, we need to balance the characteristics of the task at hand and the general rules of training or implementing a perception algorithm.
For the deep learning models, there are hyperparameters associated with each during training. These can be optimized over iterations to get a performing model that is both performing and not big in size. All the hard work would finally translate to a customized DL model for the given use case at the end of this stage, with the model’s inference accuracy and speed quantified and validated.
Stage 4: Deployment
For a robot to do the perception job properly, the algorithm or the customized DL model from Stage 3 must be plugged into the inference software pipeline, usually implemented on an ARM-based platform. The Deployment stage is considered the last mile of the perception workflow. We would then install the dependency libraries and upload software repositories and the customized DL model in the hardware.
Hardware in the loop tests are conducted to check if the requirements are met for the algorithm efficiency, accuracy, and speed. Following common industrial practice, we use docker containers for packaging the OS and the aforementioned libraries, frameworks, and files to the robot’s computing hardware.
You can find a more detailed look at our approach in “MLOps for Robots: A Primer.”

Four primary Harmony perception use cases
If the perception workflow represents the depth of the Harmony Perception Library, the use cases (as shown in the vertical aspect of the Library) constitute the breadth of the Library.
Let’s discuss some typical use cases.
Use Case 1: Object Detection and Tracking
There are ubiquitous scenarios for robots to detect and track objects in their environments. For example, an indoor autonomous mobile robot (AMR) would benefit from person and door detections to avoid dumbly hitting a closed door or awkwardly bumping into a human while in motion.
We’ve trained and deployed a YOLO model to one of our AMRs to help it recognize people and open or closed wooden and glass doors in the Fresh building. It would be interesting to add a sign and character detection capability to help the AMR to identify elevator buttons and read floor numbers for cross-floor navigation. Or we can have the AMR read the ‘BUSY’ sign from an engineer’s desk so that the AMR would know where and when not to nudge that occupied engineer.
Use Case 2: Scene Understanding and Navigation Assistance
Semantic segmentation is the task of identifying regions of an image according to each of the region’s properties. UNET is a popular DL model for 2D RGB image semantic segmentation. We can label hallways, walls, and furniture as multiple regions in images for training a customized UNET model for an office setting. The trained customized UNET model would help the AMR navigate through the drivable areas across the office space. Using Lidar point cloud data would provide the robot with an even better segmented drivable area, where we can use the PointNet++ model for the 3D semantic segmentation.
For outdoor scenarios, semantic segmentation using either 2D, 3D, or multimodal sensor fusion is critical, especially for autonomous driving vehicles to follow lanes and understand what and where objects are in their surroundings in real-time while on the road.
Use Case 3: Localization and Navigation
Then we come to the classic localization and navigation problems for robots. Visual odometry estimates the robot trajectory incrementally, step after step––how far the robot has traveled from its starting position. Visual SLAM aims to obtain a globally consistent estimate of the robot trajectory and map for its localization and navigation––where the robot is on a global map. Both visual odometry and visual SLAM are based on the image feature detection, tracking, and matching for the robot displacement and pose estimations to derive the needed information.
Two tools for performing robot localization and mapping in indoor and outdoor settings enabling autonomous navigation for an AMR include DeepVO (a popular DL-model for visual odometry) and ORB-SLAM3 (a popular visual SLAM perception package / non-learning based algorithm).
Use Case 4: Human-Robot Interactions
It seems inevitable that robots would need to be working with humans to accomplish certain tasks. For instance, in the door detection scenario, if the AMR were facing a closed door in its path, with no means of pushing or pulling the door handle, the AMR would be better off asking for an operator’s help to open the door. There are many occasions when human-robot interactions enhance work efficiency significantly, such as:
- Robots following people to a destination without a prior site map information built-in
- Robots mimicking human gestures to lift heavy boxes
- People grasping delicate objects for robots, and
- People clearing obstacles on a robot’s navigation path
It would be even more fascinating for robots to understand human actions and/or speech for ease of communication and message exchanges.
Let’s revisit the polite robot recognizing the ‘BUSY’ sign and not nudging the busy engineer in Use Case 1. If the robotic perception could figure out that the engineer was engaged in an activity by using human action recognition techniques––or even understand that the engineer would need help on something by either action or speech recognition––then this would be a super smart robotic accompaniment to humans. This might sound like a science-fiction movie but advances like it are coming gradually.
These scenarios will require robot perception to detect and understand peoples’ presence, motions, voices, etc., and to engage in semantic communication with people. There could be different ways the AMR handles the perception request if we have a comprehensive perception library, depending on the available tech stack.
The research community has been working on the human-machine-interaction and natural-user-interface problems for a while. We’re following closely with the progress to push the next engineering implementation when the occasion is right. We highly appraise the open innovation spirits of the AI research community for contributing many brilliant ML algorithms to public use. This research progress has given us excellent references for developing our engineering solutions for various use cases. And we look forward to giving back to the community by open-sourcing our work as they fit.

A pillar for future work
There are still many to-do items for our team to make this perception library for robots robust and comprehensive down the road. There definitely will be successes and failures during our endeavor. It is just the beginning and one facet of Harmony, but it is a fundamental pillar for our future work.
With a stage-gated workflow and a reservoir of ML/DL and perception algorithms to handle a magnitude of use cases, we’re hopeful that this library will lay the foundation for us to address robotic perception challenges cost-effectively. Ultimately, we’ll be able to deliver the capability of providing high-quality holistic robotic solutions to clients.
We also believe that creating the building blocks for autonomous robots will create scalability for Harmony itself and the ability to cope with new challenges using what we’ve learned from the journey, empowering us to explore untapped territories with better confidence and readiness.
What’s possible if you give the robot the correct in-time information through perception? How could we as humans potentially benefit from the robot perception-action loop getting closed nicely with our diligent work?
Apart from having intelligent and performant robots working with us, there could also be lots of blue sky and whitespace opportunities, and that’s part of what makes Harmony exciting.
We would be highly interested in speaking more about our current initiatives or discussing potential collaboration opportunities. Contact us to get started!





