Article
Adventures in Optimizing Performance

May 26, 2018 ...

Even if a programmer is very comfortable with their codebase and their technology, they won’t always be correct in determining what portions of the program are running slow. To that end, the first step for optimization with an existing system is profiling or measuring the code base. This ensures that the critical parts slowing down the system are identified and addressed.
Donald Knuth is famously reported as saying, “Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.”
Knuth is advising that programmers prioritize what to optimize. Optimization is essential to the development process. That said, it’s important to be strategic with what you optimize so you can spend your time and resources wisely. This is also similar to Eliyahu Goldratt’s concept of bottlenecks in the book The Goal: to speed up the whole system, identify the slowest part of it and resolve the slowness there, repeating this process until the desired performance has been achieved.
Knuth and Goldratt’s insights on performance allow us to determine some initial optimization principles:
Optimization Principle 1:
Don’t optimize the code unless there is a specific need to. Determine your performance and user experience requirements before jumping in.
Optimization Principle 2:
Use a profiler to determine where performance bottlenecks exist. Barring the use of a profiler, your team’s knowledge of the initial un-optimized program would be sufficient as a starting point.
Optimization Principle 3:
Identify the most important performance issues and fix them – otherwise, you’ll be wasting time optimizing in the wrong locations.
The above principles are a great starting point. But it’s important to apply your creativity and critical thinking as a developer to determine how to overcome unforeseen programming obstacles. Inevitably, they’ll arise.
Indicative of just how fluid the process of optimization is, we’ll reveal more principles and caveats throughout the post that were created and applied as unforeseen problems arose.
Bootstrapping the Optimization Process
On a recent project, we needed to create a tool to process an image, extract particular data from the image into a data model, align this data model with a pre-existing model, and convert the information into a consumable format about 2-5 times per second.
The initial algorithm clocked in at between 20-30 minutes depending on the image being processed. Attempts at applying Optimization Principle 2 failed, as using the profiler at this point failed due to timeout issues. So the first step we looked at was: “Can we change the algorithm so that it has less work to do?”
We explored the images that we were receiving, and determined that there was a lot of “noise.” Essentially, the program spent effort processing the entire algorithm against the noise that could be filtered out immediately.
Optimization Caveat 1:
A profiler can slow the performance of the code considerably, so with long running code, it might cause timeout issues that wouldn’t normally occur, It could also cause memory issues. Sometimes knowledge of the initial environment and data set is required to bootstrap the optimization process.
Optimization Principle 4:
The less work the code has to do, the faster it is. Look for ways to filter out the inputs early on.
RESULTS: Applying this filter improved the performance to take about 16 seconds, so approximately a 100x performance improvement.
Refining the Performance
Next, we followed the spirit of Optimization Principle 1, spending time determining whether the performance requirements had been met before diving deeper. While the bottleneck was removed, the requirements for performance were still not met. At this point, we began the process of looking for additional performance improvements.
Since this was not the first time such an algorithm had been implemented, we were able to pull from experience that others had with improving performance: modify the algorithm to use an inverted index.
An inverted index is a lot like a tag on a blog post. There might be multiple tags for a blog post, like “Dogs”, and “Competition.” If the tag is selected, a list of all posts that are associated with that tag are returned. Now consider the results of clicking on “Dogs”: you might get posts about “Service Dogs,” “Hunting Dogs,” etc… If you clicked “Competition,” you might get blog posts about “Horse Competitions,” “Dog Competitions,” etc… If your goal was to find a picture of a dog at a dog competition, you could take the brute force solution of looking through every blog post to find the image, or you could use the “Dogs” tag or “Competition” tag to narrow down your search.
At a very high level, the use of an inverted index allowed the entire code-base to be unmodified except for the portion that queried the pre-existing model for matches. The original query used a brute-force approach that examined every possible match; however, using an inverted index allowed me to get a subset of results that matched a particular feature in the data model. Using the inverted-index, a query was made for each feature and the union of the results gave a very narrowed down range of answers to run the expensive matching algorithm against.
Optimization Principle 5:
See if others have encountered similar problems, and leverage their work whenever possible — especially if this is done at the algorithm level.
Optimization Principle 6:
Consider how the data is structured, as it might not be the most optimal format for retrieval or consumption.
RESULTS: This change resulted in the queries taking 0.3 seconds instead of 16 seconds, or 50x performance improvement. It should be noted that this change was very acceptable in part because the building of the pre-existing model is run once at application start, but saved work during usage.
Using a Profiler
At this point the performance was adequate to focus on bug fixes, and as bugs were fixed, additional performance problems manifest themselves, and each image took about 1.5 seconds to process. Since the performance issues originally mentioned, we had been using `cProfile` module of Python to profile the application, and the findings there confirmed the approaches we had investigated for the first two rounds of performance improvements. We used the `cProfile.runctx` function to call the image processing logic, and profile only its performance, rather than the performance of the entire application. An example of the setup used for such a call:

When the application was run again, the `project_profile.stat` file was generated, and we used a module called `cprofilev` to view the results. This may need to be installed using pip, such as with `pip3 install cprofilev` to be available. To use the `cprofilev` module, enter:
`cprofilev -f project_profile.stat`, note that filename specified matches the file listed in the sample code above. With `cprofilev` running, open a browser to 127.0.0.1:4000.
The first noteworthy results were that the `round` function was being called numerous times and that the overall time this took added up to approximately 30% of the total run-time effort. Built-in libraries and functions usually have to handle more scenarios than are needed in a specific application, so may not be as ideal for an individual situation. It might be analogous to using a multi-tool when a simple pair of pliers would be more ideal.
Applying Optimization Principle 5, we investigated whether others had encountered this issue, and they certainly had. Not only that, but a proposed fix was provided.
Optimization Principle 7:
Built-in libraries and functions may not have the performance characteristics desired. This is often because they have to account for more scenarios and be more flexible than a solution tailored to your specific needs.
Optimization Caveat 2:
When applying optimizations, be sure to check numerous scenarios to ensure that an optimization doesn’t break functionality.
RESULTS: We implemented this fix, did some basic tests and were pleased to see that instead of the round function taking ~0.5 seconds, it took ~0.08 seconds. There was great value in having an optimized case. However, this change introduced a subtle bug that we did not find for weeks: it rounded properly for positive numbers, but for negative numbers, it rounded up, so -0.4999 would be -0.4. This introduced a host of subtle bugs.
More Profiler Use
When examining the results shown by cprofilev (see the excerpt below), it is possible to sort by `ncalls`, `tottime`, `cumtime`, `percall`, and `filename`. Typically when searching for a general performance bottleneck, we use the `ncalls` and `tottime`. The former indicates the number of times a function is called, and the latter indicates the total time in seconds that all calls to that function took, excluding subcalls.
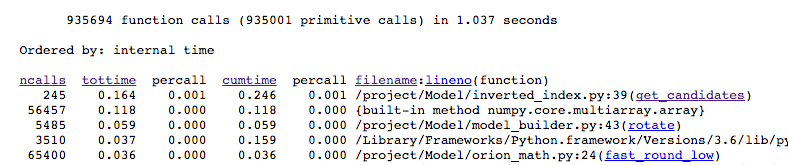
This differs from `cumtime` in that `cumtime` includes the time spent in sub-functions. In the excerpt above, there are numerous calls to the numpy’s array constructor.
In investigating where this constructor was called (2nd line in the profiler results), we determined that a bulk of the calls were within the rotate function (3rd line in the profiler results). In exploring the code, we were able to determine that a large chunk of the operations in the rotation code changed only when a pairing of parameters changed in the parent function. This would be analogous to using a library, getting a book from the shelf, using it for notes, putting it back, only to repeat the process for the exact same book ten times. Keeping the book on hand during the whole time it is needed inherently will speed up the library visit.
Optimization Caveat 3:
Performance improvements often result in less readable or maintainable code, so should be done infrequently, or in code that is unlikely to change in the future.
RESULTS: This allowed me to apply Optimization Principle 4 and push the calculations from within a loop to occurring once per parameter scenario, resulting in an acceptable 0.5 seconds, but at the cost in the readability of the rotate function (and its parent).
What Will Your Optimization Adventure Look Like?
As this post indicates, the process of optimizing code doesn’t follow an exact set of guidelines. That’s why creativity and problem-solving are such important skills for developers. While keeping principles, guidelines, and peer-generated wisdom at top of mind, it’s up to an individual dev to decide what level of optimization they need to focus on. Often, it requires creating new principles on the fly.
It is possible to responsibly improve performance early on in a project when focusing at the higher algorithmic level. However, as requirements settle down, and production needs are in sight, it may be necessary to dedicate effort for targeted improvement of performance in the system.
While the principles outlined in this article will be sufficient in many cases, there are also times when more performance is required than the programming environment allows. In such instances, rewriting the code in another language, such as C or even Assembly, or in the case of Python, using a language such as Cython.