Article
Dev Principle #5: Do Deployments Right

August 18, 2016 ...

One of the vital parts of any software project is the deployment process. It’s a central part of starting and growing the living project. Without the deployment process, your project would never see the live state it is destined for.
Whether you’re working on a simple personal project or a very active large website, the deployment should follow a clearly defined process that is reviewable, repeatable, reliable, and reversible.
The first part of making a change to live software is making a change to the code. Most projects have a location where the code is served from in order to build the most stable version. This would be your “live” code – it should always be as bug-free and stable as possible.
When making changes to the code, those changes should happen elsewhere, in a “development” environment either locally on your machine or on a server that is not visible to the public. The process in which someone takes the development code and puts it on the live site is what we mean when we refer to a “deployment process.”
Here are three useful tips for making sure your project lives a full and healthy life. These tips assume your project already uses version control software and an existing flow. We’ve written about Github Flow as a recommended approach in another post.
Reviewable
The code that was changed should be easily reviewable. All modern version control software allows the user to view which lines of a file have been edited in the last change or “commit.” The software usually highlights the lines that were added in a Green color and lines that were removed in a Red color (marked with + or – respectively for those with color deficient computers and/or eyes).
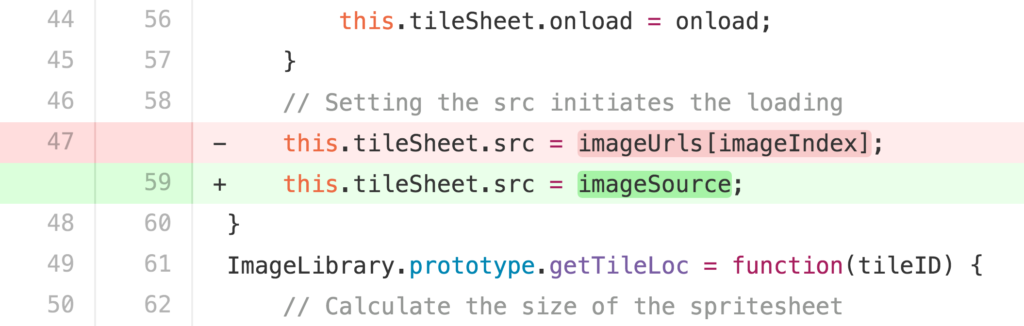
The changes made in each commit should be easily reviewable. Instead of changing multiple files and multiple lines to fix two separate issues, it is much better to fix one issue and commit that change and then fix the next issue on another commit. These are known as Atomic Commits.
Simplifying changes makes it easier for the developer and other reviewers to see exactly what is changing and why. This also helps in tracing a long-standing issue back to its source.
Repeatable
Your code deployment process should be repeatable for every change made. Whether it’s a small change with some simple user interface text or an entirely new feature being added to an application, the deployment process should work exactly the same way and produce the same expected results.
When deploying the code to a server or to the build branch, the code should be easily deployed or built locally using the same steps every time. Any user on your team following this process should be able to repeat the same steps and see their code transfer seamlessly over to the live state. The best case would be to design a deployment process that anyone on your team can repeat, and the results would be exactly the same every time.

Reliable
You may think that what your code is doing locally or on a development environment is exactly what it is going to do on the live environment; however that is not always the case. It is hard to estimate exactly what is going to happen when you finally push your code to the live state.
There may be some unknown differences between development environment and the live environment. This is why it is so important that you make sure your process is reliable down to the wire. Do your best to ensure all code environments are as similar as possible. This also includes checking that code changes are not dependent on things specific to an environment variable or package updates without clear documentation.
This will ensure a “what you see is what you get” type of feel when developing the code. Here you can have confidence that when you push bug-free code to production, you know without doubt the code will behave the way you intended.

Reversible
We are all human and we all make mistakes. If a bug does happen to slip through to the latest build or the production code, it is very important to remove it as soon as possible. Yet, some bugs may take days to work out. In that scenario, the best thing to do is to “roll back” the change, or reverse the code back to what it was before the change went out.
Now, this might not be as simple as it seems, as some projects have configuration files and environment variables outside of the version control that would need to change when the code is rolled back. These changes should be documented in the commits or wherever the standard documentation is for your given project.
The reverse process should be only minutes depending on the urgency of the project. Google demonstrated this skill when their April Fools Prank failed.

Final Tip: Make the Process Automated
A bonus tip for deployment processes: look into making the process automated.
Some deployment process require that the user compiles certain code, compresses images, or includes some “production” folder that isn’t used for testing. As we said before, humans make mistakes – as an extension of Murphy’s Law, someone is going to forget to add those folders or forget to compile the new code.
Using an automation tool will greatly reduce the risk of these things being missed. Ansible is a great example of an automation tool that can do everything needed before a deployment. It can compile, test, and even push the code for you.
However, do not make automated process the excuse to go MIA as soon as you execute them, especially if they take a long time to finish. Deployment is not done until you’ve confirmed it with your eyes, and potentially performed a post-deployment testing process. The script may fail for no good reason and you should be ready to troubleshoot when that happens.
Conclusion
These tips are only guidelines. Not all projects can have easily repeatable processes. Not all changes and upgrades can be easily reviewable. Not all bugs can be easily reverted.
However, following these guidelines will surely help make your deployment process reviewable, repeatable, and reversible. By keeping up with this, your project will live a much happier, bug-free life.