Article
Here’s why you should be using bitbucket pipelines

August 30, 2017 ...

Commonly, developer workflows include pushing code to BitBucket. From there, you run processes like testing, updating a staging server, and generating documentation. All of these processes can become very repetitive. Thankfully, they can also be automated. That’s where Bitbucket Pipelines comes in.
It’s simple – you only have to create a set of scripts that run right after you make a push to Bitbucket.
How Does a BitBucket Pipeline Work?
Here’s a quick summary:
1) A Linux virtual machine is created with a Docker configuration
2) Your source code is copied to the virtual machine
3) Your scripts are run from a bitbucket-pipelines.yml file
Here is a very basic example of the bitbucket-pipelines.yml file located in the root of the repository:
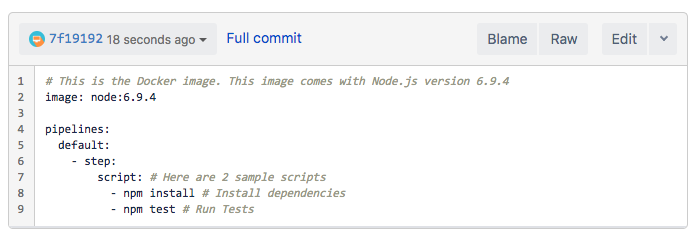
Pipelines displays the result of running those scripts, which is particularly great because of how easy it is to monitor success.
Here is an example of a successful end-to-end test process:
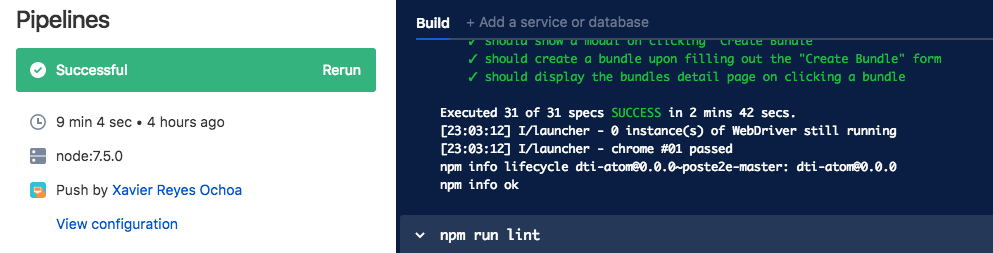
And, here is a failure:
Easy-to-read visual displays help us make sure that our processes are on the right track. Delivery progress can be monitored at a glance, so that we can quickly address errors as they pop up.
Any Command Line Can Be Used in Pipelines
Here at Fresh, we use Pipelines to automate processes like:
- Unit Testing with Jasmine, Karma and headless Chrome
- Browser Testing against Browserstack
- E2E Testing with Protractor and Browserstack
- Building Documentation with API Blueprint and push it to Apiary
- Push build to Staging and Production Servers
- Notify Slack or Email about test results
You can also run processes that require authentication against third-party services. For those cases, environmental variables are stored securely on BitBucket settings, keeping your repository free of hard-coded usernames and passwords.
Is it Worth the Effort?
Definitely!!!
Using Pipelines will save you hundreds of hours of time. It keeps developers synchronized about test results, documentation, and latest builds. Plus, you can integrate it with many other command line tools to improve productivity.
We highly recommend using BitBucket Pipelines in your workflow.